
Ten Misconceptions About Context in AI Systems
By Caber Team
If you've spent any time building RAG pipelines, deploying agents, or scaling AI beyond a proof of concept, you've heard the mantra: garbage in, garbage out. It's true as far as it goes. But it doesn't go far enough, and the gap between that truism and production reality is where most enterprise AI projects stall or fail.
The deeper problems lie in how data becomes context, that is, how fragments of data are retrieved, assembled, and presented to a model at inference time. The industry is converging on terms like "context engineering," but the conversations are riddled with assumptions that were reasonable for BI dashboards and SQL queries, and are flatly wrong for retrieval augmented generation and agentic workflows.
Here are ten of the most persistent misconceptions we've been running into.
1. "Clean data in, clean answers out." 🛀🏻
Traditional data quality, including deduplication, schema validation, or freshness monitoring at the source, is necessary but not sufficient. A chunk of text can originate from a perfectly maintained system of record and still produce a wrong answer because it was retrieved out of temporal context, combined with a conflicting fragment from another source, or served to a user who shouldn't see it for a given purpose. The failure mode isn't dirty data. It's clean data assembled into dirty context.
2. "The source of a chunk holds the ground truth." 📜
Lineage is valuable, but knowing the proximate source of a chunk — the document or table it was ingested from — doesn't tell you much when the same content exists in dozens of places. Enterprise data is duplicated at staggering rates from copying, pasting, and oversharing; studies consistently show over 95% duplication at the chunk level across large document stores. Your "source" is likely just one of many copies, and the one you indexed may not be the authoritative version. Tracing a chunk to a single document gives you a breadcrumb, not the truth. Ground truth requires understanding which copy is canonical and whether the canonical version has changed since ingestion.
3. "A document label applies to every chunk in that document." 🏷️
A classifier operating on a full document sees headings, structure, surrounding paragraphs, and metadata. A classifier operating on a chunk sees a few sentences stripped of all of that. Sensitivity labels, topic categories, and compliance tags that are accurate for a full document frequently become wrong or meaningless when applied to the individual fragments a RAG system retrieves. If your governance depends on labels assigned at the document level, it's operating on a different unit of analysis than your AI system.
4. "The meaning of a chunk lives inside the chunk." 🌴
The vast majority of chunks are not capable of identifying themselves. A sentence like "the policy covers preexisting conditions after a 12 month waiting period" could come from a current benefits guide, a superseded version, an email summarizing a proposal that was never adopted, or a competitor analysis. Which business context applies, whether the statement is current and authoritative, in short its meaning, exists in the relationships surrounding that chunk, not in the bytes that comprise it. Only a small fraction of enterprise data carries enough internal markers to identify themselves without external context.
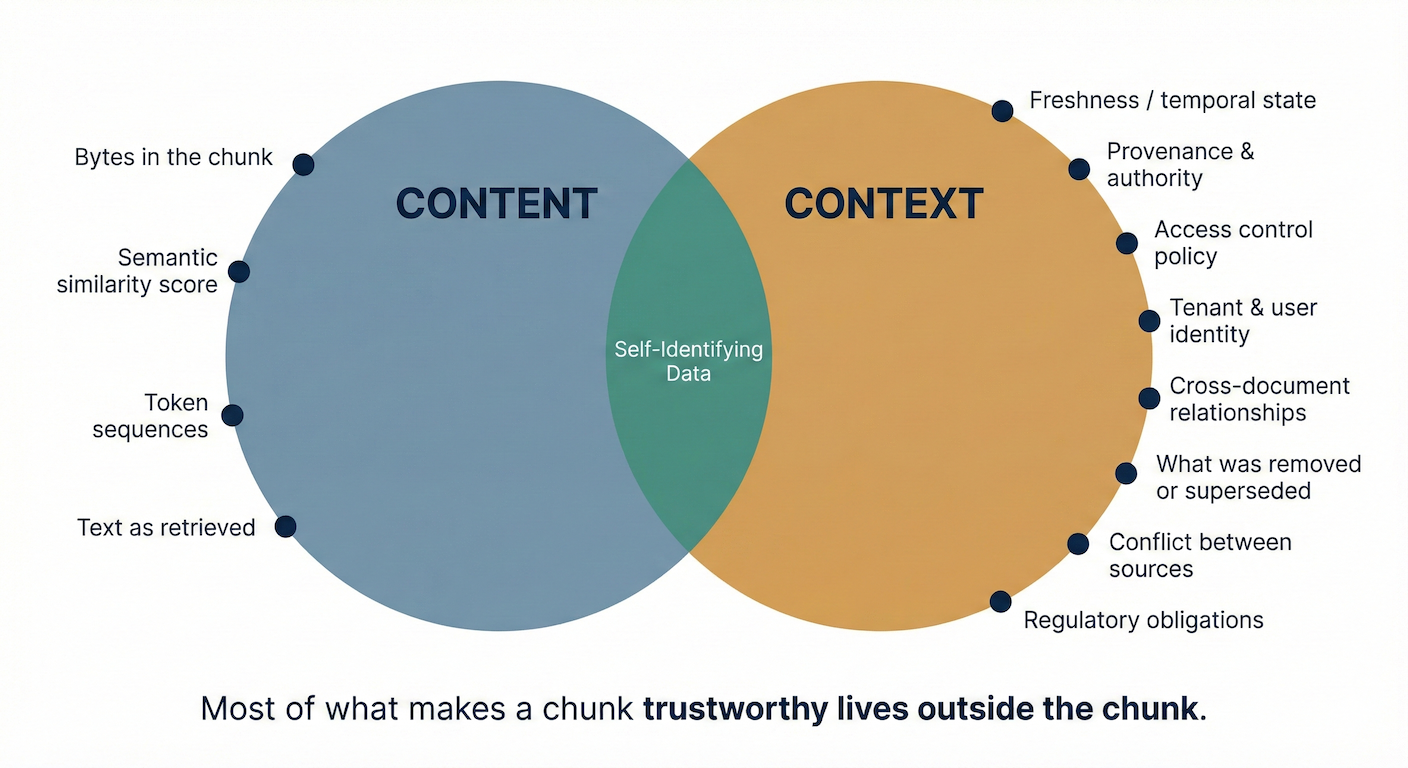
5. "Context metadata travels with the data." 🚂
It almost never does. Which user or tenant the data belongs to, what project it relates to, what classification or handling rules apply — this information typically lives in external databases, identity systems, or systems of record that are architecturally separate from the storage and retrieval infrastructure. When a chunk moves from a document store into a vector database, or from one agent's context window into another's, the metadata that gives it meaning is usually left behind. The chunk arrives naked.
6. "The most commonly used data is the most important" 🍀
Legal disclaimers, standard headers, template language, and boilerplate are one of the most common sources of noise in RAG systems. But you cannot identify them by examining a single document, because boilerplate looks identical to meaningful content in isolation. Its defining characteristic is that it appears identically across many documents. Detecting it requires analysis across documents: comparing chunks across the corpus to find the ones that repeat without variation. Without that corpus level view, your retrieval pipeline treats template language with the same weight as substantive content. Consider standard indemnification clauses in a multi-tenant SaaS platform: every customer's contract contains the same boilerplate terms. You can't decide that Tenant A shouldn't see a clause just because it also appears in Tenant B's contract, but you also can't treat it as uniquely meaningful to either.
7. "RAG chunks maintain clean source boundaries." 🧱
Chunking algorithms split text on token counts, sentence boundaries, or semantic similarity, none of which respect document boundaries. When documents from multiple sources are ingested into the same index, chunks that straddle or interleave content from different origins are common. A single chunk might contain a sentence from a regulatory filing and a sentence from an internal summary of that filing, with no marker indicating where one ends and the other begins. Boundary contamination is the norm, not the exception. And the problem compounds: a single chunk can blend multiple sources, while a single retrieval result set assembles chunks from many sources. Provenance must be tracked at both levels, per chunk and per response, and today, most systems track neither.
8. "Access control follows the data." 🎛️
In most enterprise architectures, access control policies are tied to the APIs and applications that serve the data, not to the data itself. When a user queries an application, the application enforces permissions. But when an AI agent retrieves fragments from a vector store populated by a batch ingestion pipeline with its own service account, the original access policies are nowhere in the retrieval path. The data has moved; the policy stayed behind. This is why "the RAG respects our ACLs" is almost always aspirational rather than factual.
9. "Relevance means the content matches the question." ⚠️
Semantic similarity measures whether a chunk's content is topically related to a query. But relevance for a user's actual decision can lie entirely outside the content. Consider a feature that existed in version 1 of a product and was removed in version 2. A user asking "does the product support X?" needs to know about the absence of that feature, but there's no chunk in the V2 documentation that says "X was removed." The relevant information is a contextual relationship that doesn't exist as retrievable content. Relevance, in practice, is often about what's missing, what changed, or what was superseded — none of which vector similarity can detect. This is why standard retrieval metrics like recall@k and MRR, which measure whether the "right" chunk appeared in the top results, systematically overstate retrieval quality in production: they score against content that exists, not content that should exist but doesn't.
10. "You can define all the context you need in advance." ⏱️
This is a natural assumption for anyone who has built data pipelines: if we just tag everything correctly at ingestion time, the right context will be available at query time. But you often cannot know which contextual attributes matter until you see the question. A user asking about a product feature needs version history. A user asking about a compliance obligation needs jurisdictional scope. A user asking about a customer needs entitlement status. And when new regulations take effect (as they regularly do) previously ingested data may need contextual dimensions that didn't exist in the schema when it was tagged. The context that makes a chunk trustworthy depends on the question, and no static metadata schema can anticipate every dimension of trust that a live query will require.
What These Misconceptions Have in Common
Every one of these misconceptions stems from the same root cause: treating AI's relationship with data as if it were the same as a human's or a traditional application's. Humans read documents from beginning to end and bring institutional knowledge. SQL queries hit known schemas with predictable joins. AI systems do neither. They assemble transient context from data fragments (sentences, charts, byte sequences, etc.) at runtime in response to open ended inputs, and they do it without the judgment or background knowledge that made the old assumptions safe.
Solving this requires a new layer of infrastructure because governance frameworks define policy but can't enforce it at retrieval time, and security tools control access to resources but can't track what happens to the data inside them once an AI fragments and recombines it. What some are beginning to call AI data control operates at the fragment level, at inference time, with awareness of freshness, provenance, authorization, and conflict between sources.
Better prompts can't fix this because prompts operate on whatever context the retrieval pipeline already assembled and they can't evaluate what they never saw. Smarter rerankers can't fix it because they optimize for semantic relevance, not for whether the content is current, authorized, or in conflict with another source. It's an architectural gap that sits between existing data governance frameworks and the AI systems that consume their data.
The organizations that close this gap first won't just have more reliable AI. They'll have AI they can actually trust in production.