Context Graphs for Governance
By Caber Team
Context graphs are emerging as a foundational layer for enterprise AI. They promise something enterprises desperately need: traceability, governance, and confidence as AI systems reason over increasingly complex and distributed data environments.
The vision is compelling. Context graphs can capture the relationships between data, decisions, and outcomes providing the explanatory backbone that makes AI systems trustworthy and auditable.
But as enterprises begin building context graphs in practice, a critical architectural question emerges: How should context graphs model the difference between how data exists and how data is used?
This question matters more than it might first appear. The answer determines whether context graphs become true governance infrastructure or remain sophisticated logging systems.
The Challenge: Data Existence and Data Use Follow Different Rhythms
Enterprise data does not behave uniformly. This is not an AI-specific observation, it is an inevitable property of how information is stored, evolves, moves, and is acted upon.
Consider what happens to a compliance policy document in a typical enterprise:
- It is created, versioned, and stored in a document management system
- It is copied into a data warehouse for analytics
- Portions are extracted and embedded into a vector database
- Those embeddings are retrieved during an AI agent's reasoning process
- The agent synthesizes a response that cites the policy
At each stage, the document's existence and its use follow different rhythms. The document might sit unchanged for months (existence), then be accessed dozens of times in a single day (use). A new version might be published (existence), but cached embeddings still reflect the old version during retrieval (use).
Context graphs must capture both dimensions to support AI governance.
This leads to a fundamental distinction that should shape how context graphs are architected:
- Static context describes how data exists at rest over time
- Dynamic context describes how data is accessed, moved, and used
These are not competing models. They are complementary dimensions that must be reconciled for context graphs to fulfill their promise.
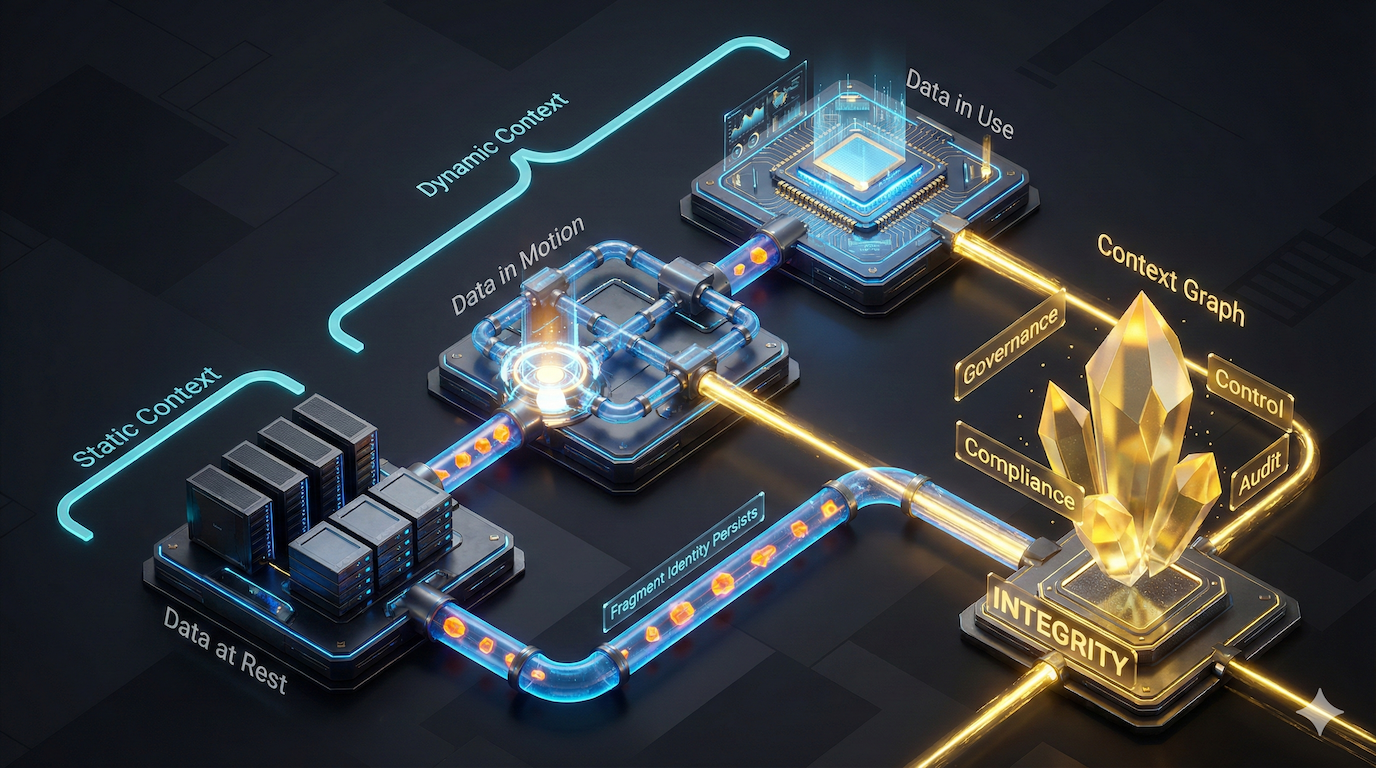
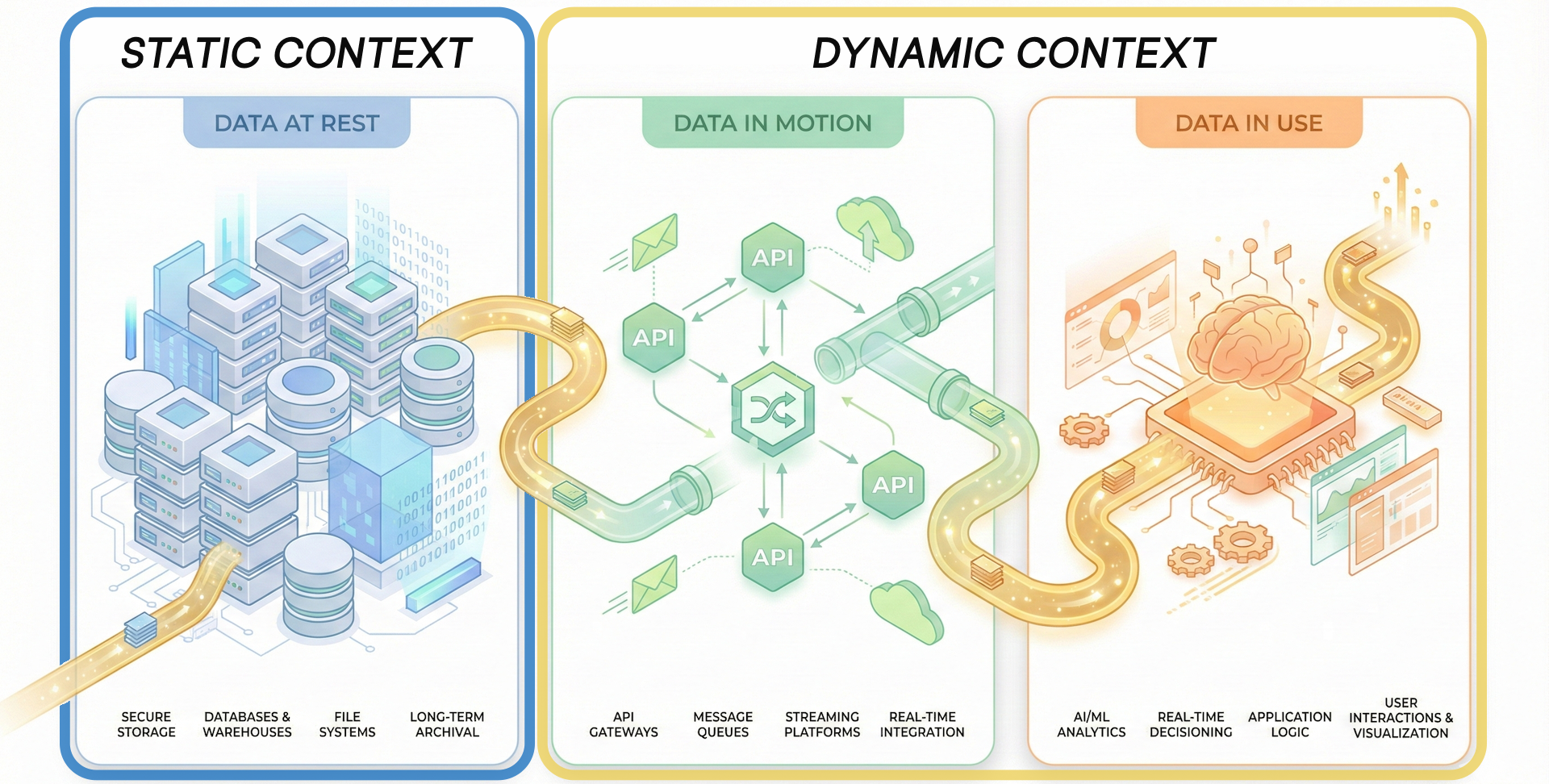 Figure 1: Static and dynamic context connect data as it's recorded to how it's used.
Figure 1: Static and dynamic context connect data as it's recorded to how it's used.
Static Context: How Data Exists
Static context tracks data as it exists across enterprise systems over time.
This includes databases, data warehouses, object stores, documents, tickets, reports, and configuration files. Static context evolves through:
- Versioning and updates
- Ownership and stewardship changes
- Retention policy applications
- Classification and tagging updates
- Schema evolution
- Duplication and synchronization across systems
Static context answers questions like:
- What was the authoritative version of this data at a given point in time?
- Who owned it then?
- What policies were bound to it while it was stored?
- How many copies exist, and where?
Static context is essential for understanding data lineage and establishing authoritative sources. But it is incomplete on its own.
Dynamic Context: How Data Is Used
Dynamic context tracks how data is accessed, transformed, and used in real time.
This includes API calls, database queries, file exports, data joins, embedding generation, retrieval operations, prompt construction, tool invocations, and agent execution traces. Dynamic context is shaped by:
- Identity and authorization at access time
- Purpose and intent declarations
- Routing and orchestration decisions
- Filtering, ranking, and selection logic
- Transformation and aggregation operations
- Redaction and policy enforcement
Dynamic context answers questions like:
- Who accessed the data and for what declared purpose?
- What transformations occurred between storage and use?
- Which specific content was selected, merged, or excluded?
- How did the AI system construct its reasoning from source materials?
Dynamic context captures decision construction, not just decision outcome.
Why Both Dimensions Matter for Governance
The most important governance questions live at the boundary between static and dynamic context.
Consider these scenarios:
Stale data in use: A policy document was updated last week (static context), but the vector embeddings used by an AI agent still reflect the previous version (dynamic context). The agent's response cites outdated guidance. This is meaning drift in action: the bytes haven't changed, but the world has, and the fragment's significance has shifted without any signal reaching the retrieval layer.
Scope drift: Data was collected and stored for one purpose (static context), but is now being used in a different context, perhaps by an AI agent serving a different business unit (dynamic context).
Duplication without propagation: A correction was made to the authoritative source (static context), but derivative copies in downstream systems were never updated, and those copies are what the AI system retrieves (dynamic context). Semantic drift compounds here: the corrected version and the stale version are no longer equivalent, but the retrieval system treats them as if they are.
Permission changes: A user's access was revoked (static context), but cached or copied data remains accessible through indirect paths (dynamic context).
In each case, examining either dimension in isolation would miss the governance violation. Static context shows compliant data; dynamic context shows compliant access patterns. Only by reconciling both can the system detect that the relationship between them has broken down.
Context graphs that collapse these dimensions into a single snapshot cannot answer the questions enterprises actually need to ask. When the world changes, governance must change with it, and only a graph that models both dimensions can keep pace.
From Explanation to Control
This framing of static and dynamic context parallels Animesh Koratana's recent distinction between a "state clock" and an "event clock" in his writing on context graphs, a signal that the industry is converging on this architectural requirement.
When context graphs model both dimensions, they unlock capabilities beyond explanation:
- Real-time policy enforcement: Detect and prevent governance violations as data is used, not after harm occurs
- Accurate audit trails: Reconstruct not just what happened, but how decisions were constructed from source materials
- Adaptive controls: Respond to changes in either dimension without relying on brittle assumptions
- Drift detection: Identify when the relationship between authoritative sources and operational copies has diverged, catching semantic drift before it reaches a user
This is the difference between a context graph that explains decisions and one that makes them.
Caber's Approach: Fragment-Level Identity Across Both Dimensions
Caber was designed around this dual-dimension reality from the start.
The key architectural insight is that reconciling static and dynamic context requires a common unit of identity that persists across both dimensions.
Traditional approaches track data at the file, record, or document level. But AI systems don't consume documents, they consume fragments. A paragraph from a policy. A row from a database. A chunk retrieved from a vector store. A snippet included in a prompt.
Caber assigns deterministic identity at the fragment level, content as small as a sentence or a database row. These fragments become the building blocks that connect data across all three states:
- At rest: Caber tracks which fragments exist in which systems, their versions, ownership, and policy bindings (static context)
- In motion: Caber observes fragments as they move between systems, copied, transformed, embedded, cached (bridging static to dynamic context)
- In use: Caber captures which specific fragments are retrieved, selected, and synthesized during AI operations (dynamic context)
Because the same fragment identity persists across all three states, Caber can deterministically answer:
- Who accessed which data
- What specific content and versions were involved
- Why particular fragments were selected over alternatives
- When context changed due to movement or transformation
- Where data originated and how it propagated
- How the decision was constructed, step by step
This is not probabilistic reconstruction or post-hoc inference. It is deterministic capture at the level AI systems actually operate.
Conclusion
Context graphs represent a genuine architectural advance for enterprise AI governance. They offer the potential to make AI systems explainable, auditable, and controllable in ways that traditional logging and monitoring cannot achieve.
But realizing this potential requires acknowledging a fundamental truth: data existence and data use are different dimensions that must both be modeled.
Static context captures how data lives across enterprise systems. Dynamic context captures how that data is accessed and transformed in practice. Governance questions, the ones that actually matter, live at the intersection of these dimensions. And because meaning drifts over time, because the relationship between a fragment and the world it describes can change without the bytes themselves changing, governance that only examines one dimension at one point in time will always be incomplete.
By modeling static context and dynamic context explicitly, and by binding them through persistent fragment-level identity, context graphs can support AI governance: not just explaining what happened, but controlling what happens next.
When context integrity is preserved across both dimensions, enterprises gain what they have been missing: visibility, control, and confidence in how AI decisions are constructed.
Caber provides fragment-level data identity for AI governance, tracking and controlling data at the sentence and chunk level across all states.