
Trust in AI Requires Trust in AI Data Use
By Caber Team
Trustworthy AI is an uncomfortable subject. It’s the most difficult question that everyone needs an answer to; but you never want an AI to answer it for you. It’s the question that no one wants to talk about; but...everyone wants to believe we have an answer to.
Garbage-in, Garbage-out
The old addage "Garbage-in, Garbage-out" is a fundamental truth in AI. If you feed an AI system bad data, it will produce bad results. With little or no stretch of the imagination you'll arrive at the corrolary: "Untrusted data in, Untrusted results out". It's a simple concept that is often overlooked in the rush to deploy AI systems.
Unfortuntaly, lack of predictability in AI systems prevents the inverse statement, "Trusted data in, Trusted results out", from being true for all results. Yet it does hold true that to have trusted results out, you must have trusted data in. This is the foundation of trustworthy AI.
The AI Trust Gap
On our journey to build a fundamentally new kind of data governance platform we’ve asked over one-hundred enterprises a simple question... “Do you Trust your Agentic AI Systems?”
95% of the time, the answer is, “of course not; but we use it anyway. We don’t have any real choice. Our competitors use AI, and we can’t sit idle while they gain an advantage” – FOMO is a real thing.
Today, trust in AI-driven processes is a key barrier. For AI to succeed at scale, individuals, companies and partners must trust and take responsibility for ensuring that processes powered by AI are safe, reliable and effective... A global survey found that 61% of people hesitate to rely on AI systems, often due to concerns over data security and third-party involvement.
- World Economic Forum, AI Governance AllianceTrustworthy AI starts and ends with your data. Data is fundamentally critical for AI models. The more data you give a model, the more information it can reason through, plan with and work with, to structure remarkable superhuman results. “Data is to AI, what oxygen is to Humans" is a universally accepted constant in the AI industry. Data security and third party involvement get to the heart of the AI Trust Gap. Was the data tampered with? Where did the data come from?
Data Lineage
The aspirational goal of Agentic AI systems is to achieve “on-par trust” with human employees, so that the business decisions being made with AI are “Trustworthy at parity” with the employees that direct the AI (or are replaced by it). This compounded trusted relationship generates an environment that should deliver radically new remarkable superhuman results for businesses. We need both the employee and the AI system to co-operate within a Circle of Trust that the business can prove, believe in and govern.
Knowing if data, and hence AI, is within this circle of trust requires knowledge of that data's lineage. This is a modern hybrid GenAI concept that converges the business goals of data governance, security, compliance, data Lineage and trust...into a single Mission critical business objective - to achieve AI Trust.
Data Knowledge Graph
At Caber, our core Gen AI thesis is that AI Trust starts and ends with data. Knowledge of data quality requires all sources of AI data and metadata consumed by Gen AI have a trusted, discoverable, lineage that is strongly connected to its security posture; at a deep granular level beyond the document container (down into the intra-document chunk, embedding and byte-segment level). We believe that trust can only be built from deeply understanding how data, metadata and segmented chunks of data flow through-out enterprise networks and Gen AI Agentic stacks (e.g. API’s, services, endpoints, databases, object stores, file systems, caches, frameworks, pipelines, etc.); and the relationships of all those data elements are graphed together in a way that trust can be deterministically computed and governed for your business. Knowing we can't rely on such a dynamic knowledge graph of data to be pre-existing in companies is the reason why building this graph efficiently and scalably is at the heart of Caber's platform.
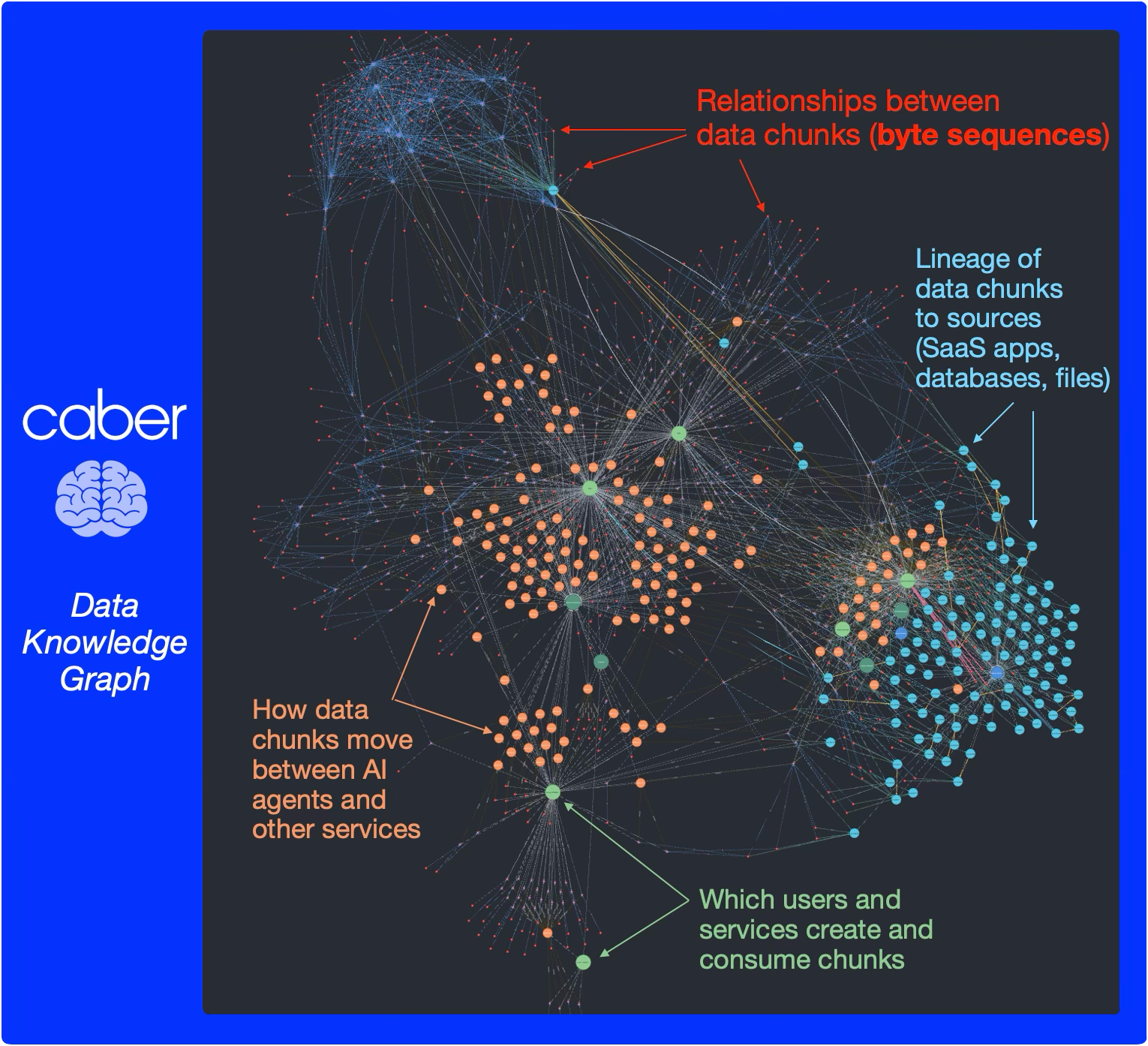
Caber links common byte-sequences found in stored objects, database records, on the network, in APIs, and used inside Agentic services to trace the lineage of data through a company's environment and identify it by the relationships it has.
Caber becomes your trusted data system that independently and neutrally governs AI Trust for your enterprise. As such Caber becomes your always-on system that runs as a core platform underneath and with your Gen AI Data systems, curating a complaint circle of trust for users as they interact and converse with your deployed Agentic AI Apps and infrastructure.
Conclusion
Gen AI Trust starts and ends with deterministic knowledge of your data. Caber delivers data knowlege, intelligence, and governance on a platform that can redact, block and deny low quality user-centric data flows before they are injected into the LLM’s context frame; deterministically preventing low performance, error-prone, inaccurate, false and confused LLM outputs. The result is higher quality LLM performance, with guaranteed private and secure AI application data operations made compliant to existing and upcomming regulations through conversational policy inputs.
We understand that Trustworthy AI requires an ‘Unstoppable Unyielding Always-on’ service based on intelligently knowing what constitutes useful, high-quality, trusted data – and can share that knowledge with other Agentic AI systems through powerful API services & insights. for Data that is utilized, accessed and flows throughout the entire Gen AI Agentic stack.
Caber is the platform that delivers this vision. We are excited to be on this journey with you.