
How Duplicate Data Kills Your RAG
By Caber Team
Retrieval Augmented Generation (RAG) has become essential for enterprise AI applications to make proprietary data available for responding to user queries. Optimizing RAG's accuracy and precision ensures relevant application responses while maintaining data security and privacy. However, these objectives often conflict. Current methods for enforcing permissions on RAG vector databases can degrade results or leak data to unauthorized users due to the need to divide enterprise data into chunks for GenAI applications.
AI's Chunked View of Data
Businesses typically handle data as files, documents, videos, or database tables, units of information we can name, organize, and manage. Metadata, such as creation time, size, creator, and applicable policies, links to these data units when stored. However, GenAI applications don't view data this way. They break down large, complex sources into smaller, semantically meaningful segments or chunks. LLMs train on chunks, vector databases store vectors created from chunks, AI applications consume data in chunks, and APIs called by AI agents move data in chunks.

Common paragraphs or chunks (blue) and unique chunks (orange) mixed in two Apple 10Q statements. Denying access to all chunks from the Q2 2024 statement in a vector database would also deny users access to much of the data in the Q2 2023 statement as well.
It seems intuitive that document-level attributes should apply to their chunks. Many AI vendors reinforce this idea. However, this assumption is fundamentally flawed and can lead to inaccurate AI responses, biased results, and compromised data security.
Data Redundancy from Chunking
Through our experience with WAN optimization, over 90% of data chunks flowing through enterprise networks are redundant. In storage systems holding enterprise data, 50%-90% of storage blocks are duplicates .
As documents are shared, edited, and converted across platforms, identical paragraphs or images often appear in multiple versions. These redundancies accumulate as authors merge comments from various drafts, circulate files, and manage revisions.
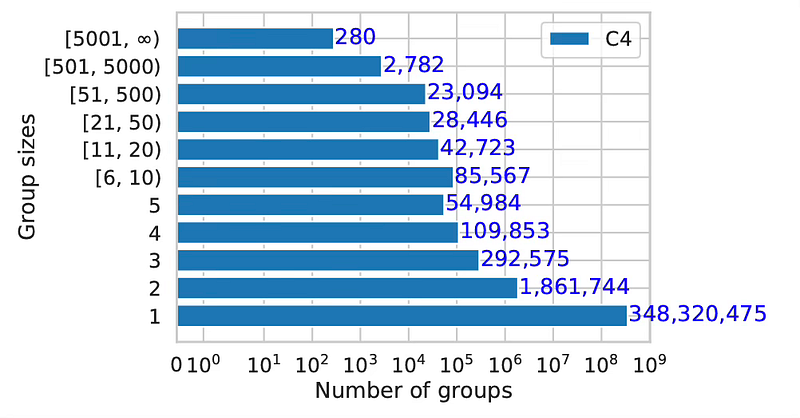
AI researchers at Google and University of Pennsylvania recorded the number of duplicate chunks seen across 348 million web documents. The number of chunks appearing only once have Group Size = 1. Eighty-five thousand chunks appeared 6-10 times. The length of chunks are not represented in this graph. Source: https://arxiv.org/abs/2107.06499
Unintended Consequences
When enterprise documents are ingested into an LLM training set or RAG vector database, identical chunks are stored only once. Identical binary sequences generate identical vectors, which vector databases use for data lookup.
However, metadata can differ significantly between documents containing the same chunks. When two such documents are ingested, the first chunk gets metadata from the first document, which the second ingestion overwrites with the second document's metadata. This can lead to problems including poor AI performance, data leakage, and biases in responses.
In multi-tenant environments, this metadata overwrite problem is especially dangerous. A multi-tenant AI system that shares retrieval infrastructure across customers may use one customer's data to answer another customer's question, not because of a failure in architectural isolation at the storage layer, but because at inference time, fragments are recombined from shared retrieval paths. Tenant boundaries that hold at the index or namespace level break down when identical chunks from different tenants collapse into a single vector with a single set of metadata. The breach surfaces through intermediaries, not logs, making it difficult to detect or audit.
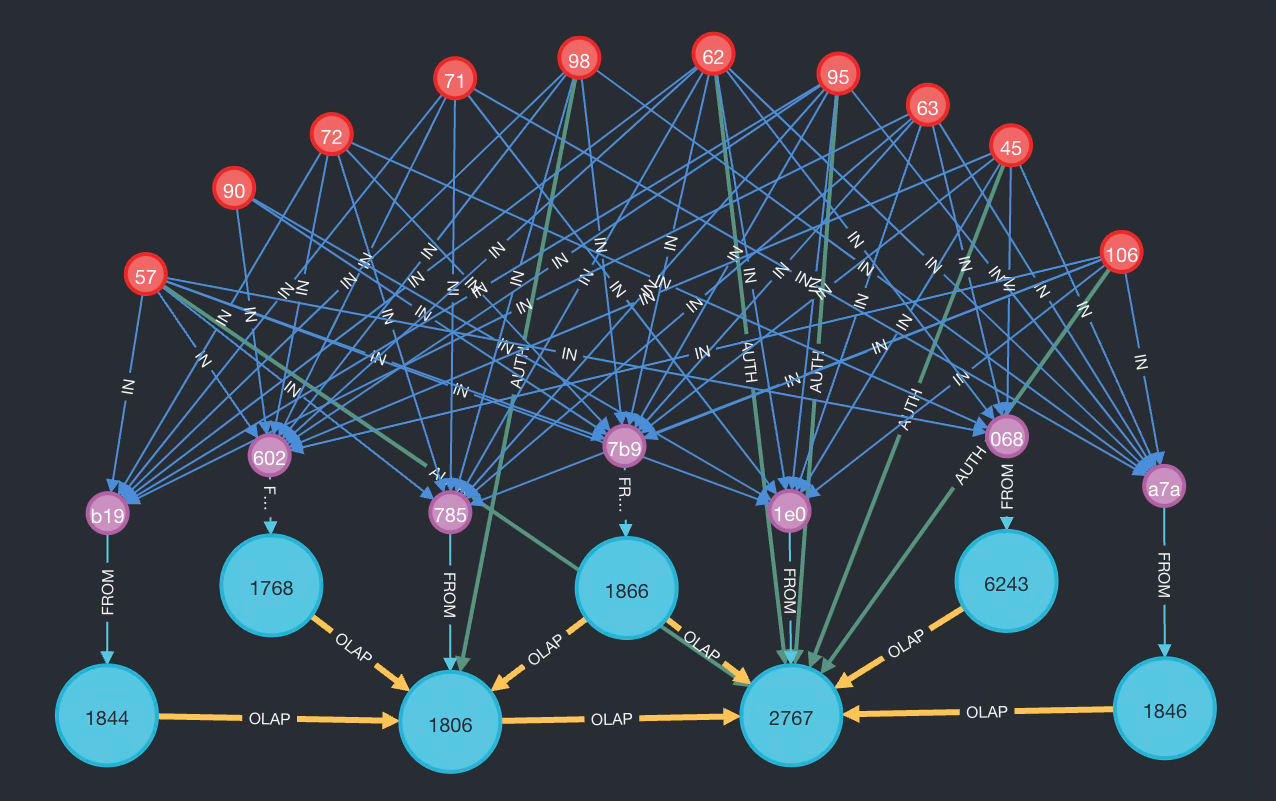
Using content-defined chunking, data in seven Apple 10Q statements (pink and blue dots) common sets of chunks (in red) can be mapped to the statements they are found in. Pink dots represent the entirety of data in each statement as would be seen by data governance systems that do not take chunking into account.
Poor AI Performance and Data Leakage
Consider a document with metadata allowing public access and another with metadata restricting access to Amy. If a common chunk exists in both, the second document's restrictive permissions might overwrite the first's open-access metadata. Bob, who should access the first document, might be denied access, while Amy could see both documents' data.
This issue, if unchecked, diminishes RAG search precision despite improvements from graph-based RAG, cascading retrieval, and other methods. Without a monitoring system, users might receive incomplete responses or unintentionally access sensitive data like coworker salaries.
Ethical Issues and Biases
As chunk sizes increase, sub-sequences within chunks become a concern. Paragraph-length chunks may contain common sentences appearing in multiple chunks. Research from Google and University of Pennsylvania shows duplicate data in LLM training sets can introduce biases and errors in responses. Repetition in prompts has been shown to cause errors in RAG systems.
Where limits exist on the number of chunks retrieved from RAG, a user query with a high similarity score to chunks containing the same sentence, may preclude other chunks relevant to the query to be dropped thus reducing response accuracy.
Lineage That Traces One Copy Is Fiction
The duplication problem has a direct consequence for data lineage. When the same chunk appears across fourteen documents, any lineage system that traces that chunk to a single source is telling you one thread of a story with fourteen chapters. Traditional lineage tools were built for a world where data moved in whole documents from one system to another. In that world, tracking a document's path from creation to storage to use was feasible. But when AI systems decompose documents into chunks, and those chunks exist in dozens of places with different metadata, ownership, and policy bindings, single-source lineage becomes fiction. It gives the appearance of traceability while hiding the full picture of where a fragment has been and what policies should govern it.
Honest lineage requires knowing every location a chunk appears, every set of metadata it carries, and every conflict between those metadata sets. Without that complete view, governance decisions are based on an incomplete record, and the confidence they project is unearned.
Conclusion
The rise of agentic AI, where autonomous AI agents collaborate and take intertwined actions, adds new layers of complexity to enterprise AI systems. These agents depend on dynamically retrieved and processed data, making robust data governance essential. As agents interact, risks like data mismanagement, bias, and leakage increase, elevating data governance from a best practice to a critical necessity.
Traditional data governance systems designed for documents, files, and tables (data at rest) are incompatible with how AI processes data. GenAI applications break data into "chunks," stripping away context and metadata needed for effective policy enforcement. To control enterprise data use in these complex AI ecosystems, governance must operate at the chunk level, addressing the unique challenges of fragmented, duplicated, and recombined data.
This means every fragment entering an AI context window must be evaluated against four questions before inference occurs:
- Is it current? Has the source been superseded, updated, or retracted since this chunk was embedded?
- What is its provenance? Where did this chunk originate, where else does it appear, and which source is authoritative?
- Is it authorized? Does the requesting user have permission to access this specific fragment, given the union of all its metadata across every location it appears?
- Does it conflict? Do the metadata, policies, or classifications from different sources of this chunk contradict each other, and if so, how should that conflict be resolved?
Without answering these four questions at the chunk level, enterprises face degraded AI precision, reduced reliability, and potential data breaches, risks amplified by agentic AI's interconnected nature and by the tenant isolation failures that duplication-driven metadata overwrites create in multi-tenant deployments.