
AI Velocity Nobody Can Secure (MCP Part 1)
By Caber Team
The AI ecosystem is growing faster than any IT technology in history. The Model Context Protocol (MCP) reached over 6,000 servers in its first year, nine times faster than the API boom that reshaped enterprise architecture. But the real problem isn't speed; it's granularity. AI agents operate at sentence level, extracting and recombining data fragments that document-level security tools can't see. The question isn't whether MCP will outpace traditional security; it already has. The question is whether enterprises can understand data identity at the granularity AI actually operates before the next wave of automation makes the problem exponentially worse.
The 9× Growth Problem
In the 2000s, it took seven and a half years for public APIs to reach roughly 6,000 deployments. In 2025, MCP hit the same milestone in 11 months. This isn't progress, it's acceleration without governance.
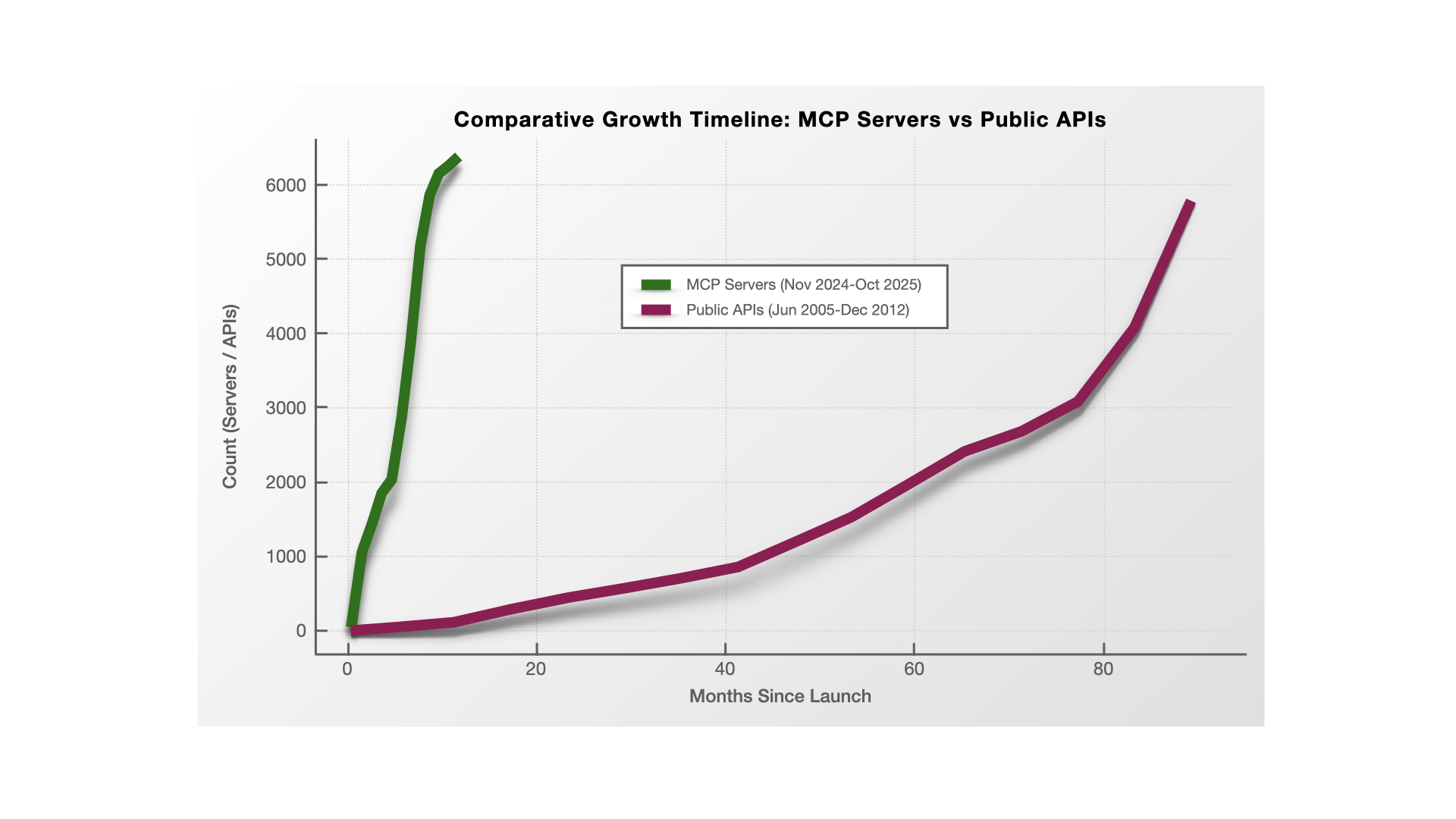
Figure 1: MCP adoption trajectory compared to historical API growth. MCP reached ~6,000 servers in just 11 months versus 90 months for APIs. This represents a 9× faster deployment velocity (575 servers/month vs 65 APIs/month). While APIs took 3.5 years to publish their first security standard, MCP achieved this in 5 months, demonstrating both accelerated growth and compressed governance timelines.
This data reveals a dynamic complexity problem: the ecosystem is expanding at a rate no security or audit process can match. Each MCP server introduces new data paths, new toolchains, and new identity relationships, all changing faster than governance frameworks can adjust.
The Human Capacity Cliff
Even if every organization dedicated staff to review new servers and policies, the math doesn't work.
| Metric | Value |
|---|---|
| Estimated new MCP servers per month | ~575 |
| Average manual audit capacity per enterprise | ~50 servers / month |
| Percentage unreviewed | >90% |
This is the first sign of structural ungovernability, when system change rates exceed the human capacity for understanding. Governance isn't failing because enterprises are careless; it's failing because the system's speed makes comprehensive oversight impossible.
Why Existing Security Models Don't Scale
Traditional Zero Trust and API governance rely on predictable endpoints and static identities. MCP, however, connects ephemeral AI agents to dynamic tool servers, forming fluid relationships that can't be enumerated ahead of time. That breaks the assumptions behind most access controls:
| Control Principle | What Works for APIs | Why It Breaks for MCP |
|---|---|---|
| Endpoint-based policies | Static URL / method mapping | Agents compose new routes dynamically |
| Role-based access | Fixed user-to-resource mapping | Agents act across roles & tenants |
| Manual review | Human review cadence (monthly) | Machine reconfiguration (minutes) |
MCP is not merely faster; it's qualitatively different. It replaces predictable architecture with continuous recomposition. Traditional security models struggle with this because they were designed for systems where change happens slowly enough for humans to review each modification.
Evidence of the Data Identity Crisis
By mid-2025, multiple independent studies revealed that most MCP servers had minimal governance:
| Source | Finding |
|---|---|
| Equixly MCP Vulnerability Scan (2025) | 43% of tested servers vulnerable to command injection |
| Docker Security Analysis | 33% allowed unrestricted URL fetches |
| Astrix Labs | 60% lacked authentication for one or more endpoints |
None of these issues are exotic zero-days, they're failures to understand what data is moving and whether it should be. AI agents don't consume documents; they use sentences, paragraphs, and tables extracted from them. Traditional security tools work at the document level, missing what agents actually access.
The lesson from the API era still applies: you can't control what you don't understand. The difference is velocity. MCP compresses the timeline from exposure to exploitation from years to weeks.
The Governance Paradox
Every enterprise faces a paradox: enforcing strong controls early breaks functionality, but waiting for maturity leaves exposure. API security teams learned this the hard way, enforcing strict scopes too early causes mass outages; enabling them too late, vulnerabilities.
MCP accelerates that paradox. Every new tool added by an AI agent redefines what "normal" looks like. Security teams can't manually validate every relationship, and automation without context just amplifies the chaos.
This leads to a fundamental realization:
You can't authorize data use if you don't know what the data is.
Traditional security authorizes access to resources. AI security requires understanding data identity, what a sentence means, where it came from, and whether it's relevant to the question being asked.
Quantifying the Risk Horizon
| Factor | API Ecosystem (2010s) | MCP Ecosystem (2025) | Consequence |
|---|---|---|---|
| Growth velocity | Moderate (linear) | Explosive (exponential) | Control can't keep pace |
| Granularity | Document/API level | Sentence/paragraph level | 100-1000× finer access control needed |
| Identity complexity | User & app | User, agent, data, context | Authorization requires both user AND data identity |
| Data transformation | Mostly static | Continuous (AI processing) | Classification labels don't survive |
The result: systems that operate at sentence-level granularity being secured with document-level tools. It's not just a speed problem, it's a fundamental mismatch between where AI operates and where security controls exist.
The hard truth is that we can’t build a new firewall for every new AI resource. Each innovation, LLMs, agents, RAG, MCP, A2A, and so on, demands another control surface, another governance model, another cycle of catch-up. That strategy can’t scale.
Data is the invariant. It doesn’t evolve as fast as the tools that use it, and, becasueit's the fuel for AI, it’s the one layer that can govern AI innovation. If we can control how data is used, not just where it resides, we break the velocity trap entirely.
The Path Forward: Understanding Data Identity
The traditional model of security, authorize access to resources, no longer works when AI agents extract and recombine data at sentence-level granularity.
The emerging approach requires answering a question that document-level security never had to address: What is this data?
Not "what does it look like" (classification) or "where does it live" (resource authorization), but what it actually is, its meaning, context, provenance, and relationships.
This requires:
- Triangulation: Determining data identity by mapping relationships, not matching patterns. Understanding what a sentence means based on where it came from, how it's been used, and what it connects to.
- Dual validation: Verifying both security (is the user authorized?) AND quality (is this data relevant to the question?). AI needs both to work correctly.
- Sentence-level granularity: Operating at the same level AI operates, not one or two levels above it.
Companies like Caber Systems are building platforms based on this triangulation approach, using knowledge graphs similar to GraphRAG systems to continuously map data identity at the sentence level. The philosophy: you can't authorize data use until you understand what the data is.
| Phase | Traditional Model | Data Identity Model |
|---|---|---|
| Step 1 | Define resource policies | Triangulate on data identity |
| Step 2 | Enforce at gateway | Validate authorization AND relevance |
| Step 3 | Audit post-incident | Continuous lineage tracking |
| Step 4 | React to breaches | Adapt as data/policies evolve |
This isn't about seeing more, it's about understanding what you're seeing at the granularity that matters.
Closing Thought
APIs were the first proof that innovation outpaces security. MCP proves that document-level security can't protect sentence-level operations.
The first step toward governing AI ecosystems isn't better enforcement; it's operating at the right granularity. Organizations that understand data identity at the sentence level, what data means, not just where it lives, will be able to authorize AI data use effectively. Those that continue applying document-level controls will face the same crisis that plagued the early API era, but compressed into months instead of years.
The question isn't whether to secure AI. It's whether to secure it at the level AI actually operates.
Next in the series: Part 2, The Myth of Progress: Why New Protocols Repeat Old Vulnerabilities
We'll explore why MCP's security improvements underway mirror the API world's evolution, and why history suggests that better design doesn't prevent widespread vulnerabilities when adoption outpaces implementation.