
Why Securing MCP Servers is the Wrong Approach (Part 3)
By Caber Team
This is Part 3 of a series on MCP security. Part 1: AI Velocity Nobody Can Secure examines why MCP adoption is outpacing every governance framework built to contain it. Part 2: Old Vulnerabilities are New Again shows why the same vulnerabilities that plagued APIs are recurring in MCP at compressed timelines.
Enterprises still govern access as if endpoints and servers define risk. Now agent and MCP firewalls have just joined the security stack, adding yet another layer to the long progression of resource level controls. In the API era it was safe to assume an application's URL or method could be linked to the data it returned. But in the world of MCP and AI agents, data, not resources or code, define the unit of agent action. There is no correlation between the endpoint and the data it returns.
Access control that stops at the endpoint is now an illusion of safety. The real challenge is not stopping access to resources, it is understanding and controlling how data is used.
How We Got Here and What History Teaches
Security has always evolved by wrapping controls around whatever layer exposed risk. Each new era brought its own perimeter: networks, applications, APIs, and now AI agents.
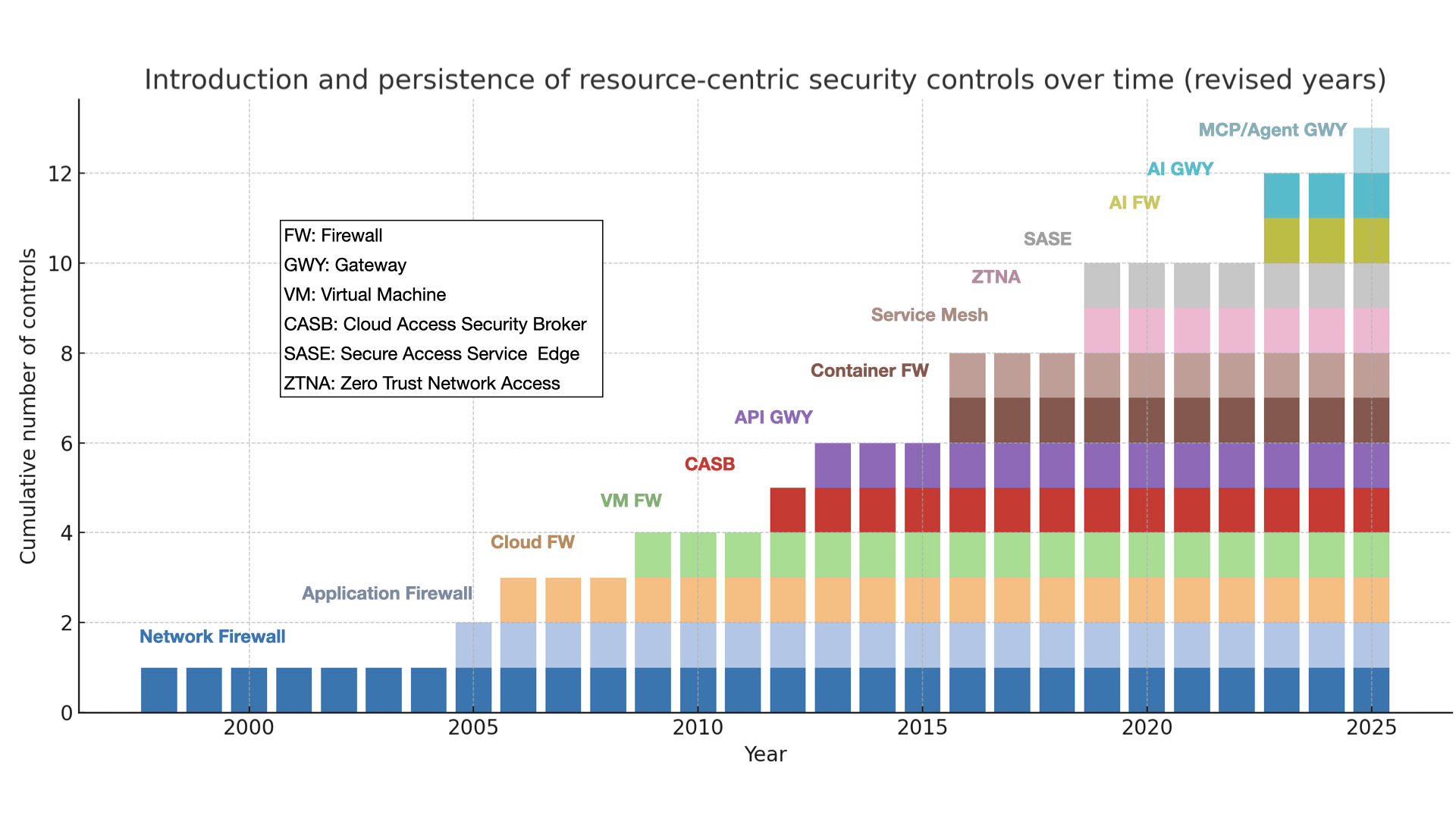 Figure 1 A quarter century of resource centric controls culminating in Agent and MCP firewalls
Figure 1 A quarter century of resource centric controls culminating in Agent and MCP firewalls
At first glance the trend looks like steady progress. In reality it is a warning. Every new type of firewall or gateway has required its own unique set of rules written in its own syntax and applied within its own context.
To protect how data is used, security teams have to translate business and compliance requirements into separate rule sets for every layer in the stack. Each layer interprets those rules differently. One looks at IP addresses, another at URLs, another at roles or tokens. No two layers ever agree on what a rule truly means.
The result is a rule explosion and an impossible maintenance problem. Policies drift out of alignment and enforcement becomes inconsistent. The number of rules that must be written, reviewed, and reconciled grows faster than the number of controls meant to keep things safe.
Adding Agent or MCP firewalls does not solve this. They extend the same resource centric model that created the problem in the first place. They may block requests, but they do not control how the data those requests use is combined, shared, or reused.
Why Resource Based Authorization Fails in AI Ecosystems
Traditional security assumes:
- Resources are static
- Access equals intent
- Policy boundaries are knowable
In MCP systems, none of these are true.
| Old Assumption | AI Reality | Implication |
|---|---|---|
| Static resources | Dynamic tool composition | Endpoints change at runtime |
| Access = intent | Agents act autonomously | Intent is inferred, not declared |
| Known boundaries | Context recombines continuously | Policies must adapt in real time |
An MCP server may expose hundreds of tools, each able to reach into data stores in unpredictable ways. Authorizing which tool is used tells us nothing about what data it touches, where it came from, or why it was requested.
When MCP calls carry only an agent's credentials, policy engines lose sight of the human behind the request. Rules written for users or roles no longer apply, because the system cannot distinguish who the data is truly serving.
Data Entanglement: The New Security Surface
In traditional systems, data could be neatly contained within application boundaries. Now, the same content is duplicated, embedded, and remixed across files, APIs, and vector databases.
Without a persistent way to identify what the data is and what it relates to, resource level control becomes meaningless. The same paragraph may appear in five systems, each with different owners, rules, and retention requirements. When one copy is restricted, others remain exposed.
The Governance Vacuum This Creates
APIs once governed through endpoint scope, allowing or denying access to paths such as /finance or /hr. MCP cannot. A single call like summarize_customer_revenue() may blend data from finance, CRM, and analytics in one step. To existing security systems, that looks fine, but it may combine regulated financial data with public information in violation of policy.
When policies cannot follow the data, governance collapses into guesswork.
In agentic systems, no single application owns the data flow. Permissions must come from the data itself, from the relationships that define what it represents, where it originated, and how it connects to other information. Only by understanding these relationships can the system decide whether combining or sharing the data is allowed.
What Data Use Control Actually Means
Controlling data use is not simply a finer grained resource policy, to stop bad things from happening. Instead of asking who can call this endpoint, the question becomes is this the best data the user is authorized to access. Answering that requires knowing the relationships each piece of data has to the systems, users, and policies around it.
When rules are tied to data relationships, they adapt naturally to how the data is used. Policies can be as much about relevance and quality as they can about authorization and access control. The result is not only safer outcomes but also higher quality and more complete answers from AI systems.
The Knowledge Graph Approach
Modern AI systems already use knowledge graphs to model connections between entities, documents, and facts. Those same graph techniques can describe how enterprise data relates to its sources, to other data, to users, and to governing policies. By analyzing these relationships deterministically at the level of sentences, tables, or code fragments, organizations can finally control how data is used rather than where it happens to reside.
Tracing Data Across Agent Chains, Not Just Call Chains
Multi-agent systems introduce a problem that call-chain observability alone cannot solve. When Agent A calls Agent B, which calls Agent C, existing tracing tools can record the sequence of invocations. But they cannot answer the question that governance requires: which specific data fragments moved through that chain, and on whose behalf?
Caber follows fragment identity through agent chains by maintaining the connection between the data and the human who initiated the request, without requiring credential passing between agents. When a user asks a question that triggers a multi-agent workflow, Caber's knowledge graph records which fragments each agent retrieved, which it passed downstream, and which were ultimately assembled into the response. The originating user's identity stays bound to the data throughout, not through token delegation or credential forwarding, but through the graph's record of which human request set the chain in motion and which fragments served that request at every step.
This means governance decisions at any point in the chain can account for who the data is actually serving, not just which agent is holding it. A fragment that Agent C retrieves from a vector store can be evaluated against the originating user's permissions and the purpose of the original query, even though Agent C has no direct knowledge of either. The graph provides the context that the call chain cannot.
From Resource Boundaries to Data Use Control
Resource based controls keep multiplying because they chase symptoms, not causes. The next generation of governance will focus on controlling the motion and combination of data itself. That means identifying data precisely, mapping its relationships, and enforcing rules that determine how it can be used across any system.
This is the foundation of data centric Zero Trust, where control of data use replaces the illusion of perimeter defense.
Closing Thought
Agent and MCP firewalls are the newest signs of an industry stuck protecting the wrong thing. After 25 years of building walls around resources, it is time to focus on controlling how data is used. Only then can enterprises move from preventing access to governing use, the real measure of control in the age of autonomous AI.
Next in the series Part 4: The Hidden Actor, When Agents Obscure the User Behind the Request